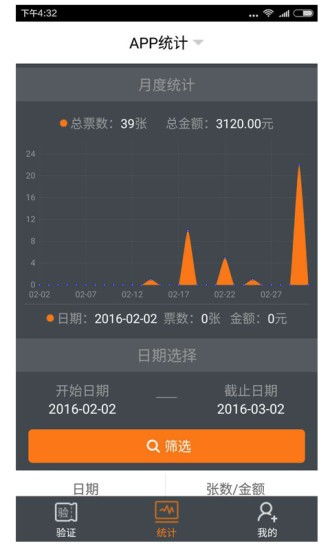
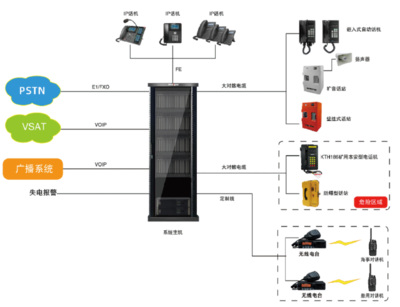
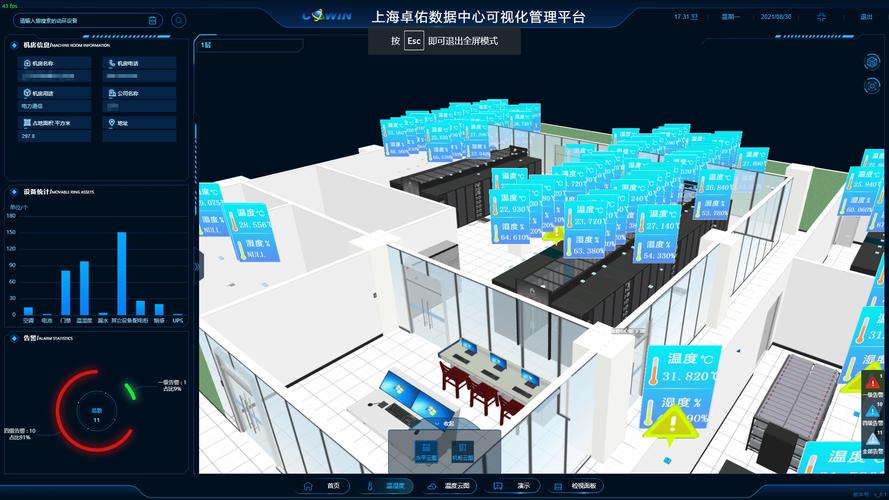
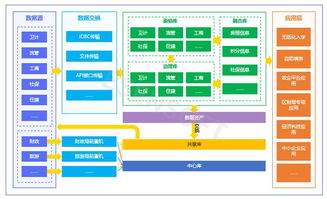
大數據已成為現代科技與商業決策的核心驅動力。本文將從大數據的基本概念出發,深入解析分布式計算、服務器集群及數據處理服務三大關鍵組成部分。
一、大數據的基本概念
大數據通常指規模龐大、類型多樣、生成速度快且價值密度低的數據集合。其核心特征可概括為“4V”:數據量大(Volume)、數據類型多樣(Variety)、數據生成速度快(Velocity)以及價值密度低(Value)。大數據技術旨在從這些海量數據中提取有價值的信息,支持智能決策與業務創新。
二、分布式計算:處理海量數據的核心引擎
分布式計算是大數據處理的基石。其核心思想是將大規模計算任務分解為多個子任務,分配給多臺計算機并行處理,從而顯著提升計算效率。分布式計算框架(如Hadoop MapReduce、Apache Spark)通過任務調度、容錯機制和數據分區,確保復雜計算任務在可接受的時間內完成。例如,在用戶行為分析中,分布式計算能夠快速處理數億條日志記錄,識別出關鍵模式。
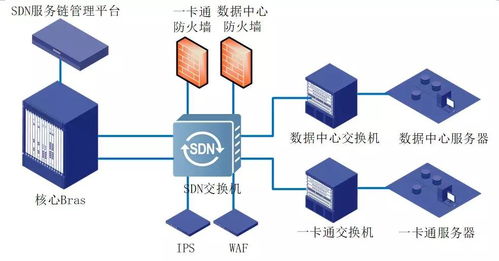
三、服務器集群:支撐大數據的基礎設施
服務器集群是由多臺服務器通過網絡互聯構成的系統,共同提供計算和存儲資源。在大數據應用中,集群通過橫向擴展(增加節點)應對數據增長,并具備高可用性和負載均衡能力。典型的集群架構包括主節點(負責協調)與工作節點(執行具體任務)。例如,Hadoop HDFS(分布式文件系統)依賴集群存儲數據,確保數據冗余與快速訪問。
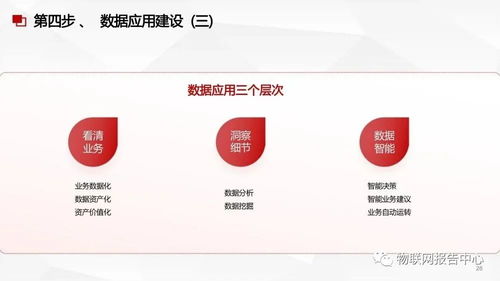
四、數據處理服務:從原始數據到洞察價值
數據處理服務涵蓋數據采集、清洗、存儲、分析與可視化等環節。服務化架構(如云平臺上的AWS EMR、Google BigQuery)讓用戶無需管理底層基礎設施,即可高效處理數據。這些服務通常集成機器學習工具,支持實時流處理(如Apache Kafka)與批處理,幫助企業實現預測分析、個性化推薦等應用。
大數據技術通過分布式計算與服務器集群的協同,結合專業的數據處理服務,賦能各行各業挖掘數據潛力。隨著人工智能與物聯網的發展,大數據生態將進一步演進,成為數字化時代的核心基礎設施。